Troubleshooting common VMware ESX host server problems
VMware ESX/ESXi Monitoring
Gain in-depth insights on CPU, memory, disk, datastore, and network of your ESX/ESXi servers. Receive instant alerts when the server is down or when thresholds are exceeded.
Add a VMware ESX/ESXi Monitor
- Go to the Admin tab and select VMware ESX/ESXi Server (under Virtualization) in Add Monitor page.
- Specify the following information to add the VMware ESX/ESXi Server monitor:
- Display Name: Provide a display name to identify the VMware ESX/ESXi Server monitor.
- ESX/ESXi host: Specify the IP address or Domain Name for the ESX/ESXi host.
- Port: Specify the designated port number of the managed host.
- Username: Enter the user account for the system.
- Password: Enter the credentials associated with your user account.
- Monitoring locations: Select the location profile from the drop-down list from where the ESX/ESXi can be monitored.
- Monitor Groups: Associate the ESX/ESXi monitor with a monitor group. Choose an existing monitor group or create a new one. To create a new monitor group, read our product documentation.
- Dependent on monitor: From the drop-down, select the dependent monitor you want. Site24x7 will suppress alerts for the configured ESX/ESXi monitor if the dependent monitor is already down.
- Toggle yes or no to Discover and Auto-add resources. By enabling this, the resources running on this ESX/ESXi host will be discovered automatically and added as individual monitors for monitoring.
- Virtual machines: Toggle Yes to enable monitoring virtual machines.
- Resource pools: Toggle Yes to enable monitoring resource pools.
- Datastores: Toggle Yes to enable monitoring datastores.
- Specify the following details for Configuration Profiles:

- Threshold and Availability: Select a threshold profile from the drop-down list or choose the default threshold set available and get notified when the resources cross the configured threshold and availability. To create a customized threshold and availability profile, refer Threshold and Availability.
- Notification Profile: Choose a notification profile from the drop-down list or select the default profile available. Notification profile helps to configure when and who gets notified in case of downtime.
Refer Notification Profile to create a customized notification profile. - User Alert Group: Select the user group that needs to be alerted during an outage.
To add multiple users to a group, see User Groups. - Tags: Associate your monitor with predefined Tag(s) to help organize and manage your monitors creatively. Learn how to add Tags.
- IT Automation: Select an automation to be executed when the VMware ESX/ESXi server is down / trouble / up / any status change / any attribute change. The defined action gets executed when there is a state change and selected user groups are alerted. To automate corrective actions on failure
- Third Party Integration: Associate your monitor with a pre-configured third-party service. It lets you push your monitor alarms to selected services and facilitate improved incident management.

- Click Save.

Get a grip on potential VMware ESX host server problems including the purple screen of death, a frozen service console, and rebuilding your network configurations after they've been lost.
Panicking at the onset of a high impact technical problem can cause impulsive decision making that enhances the problem. Before trying to troubleshoot any problem, pause and relax to approach the task with a clear mind, then address each symptom, possible cause and resolution appropriately.
ESX/ESXi hosts do not respond and is grayed out (1019082)
In this series, I offer solutions for many common problems that arise with VMware ESX host servers, VirtualCenter, and virtual machines in general. Let's begin by addressing common issues with VMware ESX host servers.
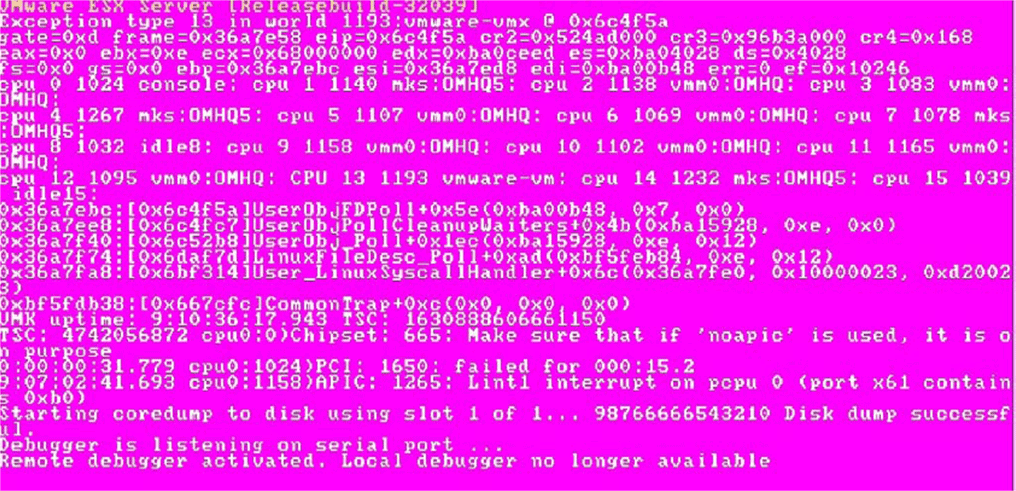
Windows server administrators have long been familiar with the dreaded Blue Screen of Death (BSOD), which signifies a complete halt by the server. VMware ESX has a similar state called the purple screen of death (PSOD) which is typically caused by hardware problems or a bug in the VMware code.
Troubleshooting a purple screen of death
When a PSOD occurs, the first thing you want to do is note the information displayed on the screen. I suggest using a digital camera or cell phone to take a quick photo. The PSOD message consists of the ESX version and build, the exception type, register dump, what was running on each CPU at the time of the crash, back-trace, server up-time, error messages and memory core dump info. The information won't be useful to you, but VMware support can decipher it and help determine the cause of the crash.
Unfortunately, other than recording the information on the screen, your only option when experiencing a PSOD is to power the server off and back on. Once the server reboots you should find a vmkernel-zdump-* file in your server /root directory. This file will be valuable for determining the cause. You can use the vmkdump utility to extract the vmkernel log file from the file (vmkdump –l ) and examine it for clues as to what caused the PSOD. VMware support will usually want this file also. One common cause of PSOD's is defective server memory; the dump file will help identify which memory module caused the problem so it can be replaced.
Checking your RAM for errors
If you suspect your system's RAM may be at fault you can use a built-in utility to check your RAM in the background without affecting your running virtual machines. The RAM check utility runs in the VMkernel space and can be started by logging into the Service Console and typing Service Ramcheck Start.
While RAM check is running it will log all activity and any errors to the /var/log/vmware directory in files called ramcheck.log and ramcheck-err.log. One drawback, however, is that it's hard to test all of your RAM with this utility if you have virtual machines (VMs) running, as it will only test unused RAM in the ESX system. A more thorough method of testing your server's RAM is to shutdown ESX, boot from a CD, and run Memtest86+.
Using the vm-support utility
If you contact VMware support, they will usually ask you to run the vm-support utility that packages all of the ESX server log and configuration files into a single file. To run this utility, simply log in to the service console with root access, and type "vm-support" without any options. The utility will run and create a single Tar file that will be named "esx- --
Alternatively, you can generate the same file by using the VMware Infrastructure Client (VI Client). Select Administration, then Export Diagnostic Data, and select your host (VirtualCenter data optional) and a directory on your local PC to store the file that will be created.
Using log files for troubleshooting
Log files are generally your best tool for troubleshooting any type of problem. ESX has many log files. Which ones you should check depends on the problem you are experiencing. Below is the list of ESX log files that you will commonly use to troubleshoot ESX server problems. The VMkernel and hosted log files are usually the logs you will want to check first.
- VMkernel - /var/log/vmkernel – Records activities related to the virtual machines and ESX server. Rotated with a numeric extension, current log has no extension, most recent has a ".1" extension.
- VMkernel Warnings - /var/log/vmkwarning – Records activities with the virtual machines, a subset of the VMkernel log and uses the same rotation scheme.
- VMkernel Summary - /var/log/vmksummary - Used to determine uptime and availability statistics for ESX Server; readable summary found in /var/log/vmksummary.txt.
- ESX Server host agent log - /var/log/vmware/hostd.log - Contains information on the agent that manages and configures the ESX Server host and its virtual machines. (Search the file date/time stamps to find the log file it is currently outputting to, or open hostd.log, which is linked to the current log file.)
- ESX Firewall log - /var/log/vmware/esxcfg-firewall.log – Logs all firewall rule events.
- ESX Update log - /var/log/vmware/esxupdate.log – Logs all updates done through the esxupdate tool.
- Service Console - /var/log/messages - Contains all general log messages used to troubleshoot virtual machines or ESX Server.
- Web Access - /var/log/vmware/webAccess - Records information on web-based access to ESX Server.
- Authentication log - /var/log/secure - Contains records of connections that require authentication, such as VMware daemons and actions initiated by the xinetd daemon.
- Vpxa log - /var/log/vmware/vpx - Contains information on the agent that communicates with VirtualCenter. Search the file date/time stamps to find the log file it is currently outputting to or open hostd.log which is linked to the current log file.
As part of the troubleshooting process, often times you'll need to find out the version of various ESX components and which patches are applied. Below are some commands you can run from the service console to do this:
- Type vmware –v to check ESX Server version, i.e., VMware ESX Server 3.0.1 build-32039
- Type esxupdate –l query to see which patches are installed.
- Type vpxa –v to check the ESX Server management version, i.e. VMware VirtualCenter Agent Daemon 2.0.1 build-40644.
- Type
to check the ESX Server VMware Tools installed version – i.e., VMware-esx-tools-3.0.1-32039.rpm –qa | grep VMware-esx-tools
If all else fails, restart the VMware host agent service
Many ESX problems can be resolved by simply restarting the VMware host agent service (vmware-hostd), which is responsible for managing most of the operations on the ESX host. To do this, log into the service console and type service mgmt-vmware restart.
NOTE: ESX 3.0.1 contained a bug that would restart all your VMs if your ESX server was configured to use auto-startups for your VMs. This bug was fixed in a patch for 3.0.1 and also in 3.0.2, but appeared again in ESX 3.5 with another patch released to fix it. It's best to temporarily disable auto-startups before you run this command.
In some cases restarting the vmware-vpxa service when you restart the host agent will fix problems that occur between ESX and both the VI Client and VirtualCenter. This service is the management agent that handles all communication between ESX and its clients. To restart it, log into the ESX host and type service vmware-vpxa restart. It is important to note that restarting either of these services will not impact the operation of your virtual machines (with the exception of the bug noted above).
Fixing a frozen service console
Another problem that can occur is your Service Console can hang and not allow you to log in locally. This can be caused by hardware lock-ups or a deadlocked condition. Your VMs may continue to operate normally when this occurs, but rebooting ESX is usually the only way to recover. Before you do that, however, try shutting down your guest VMs and/or using VMotion to migrate them to another ESX host. To do this, use the VI Client by connecting remotely via SSH or by using one of alternate/emergency consoles, which you can access by pressing Alt-F2 through Alt-F6. You can also press Alt-F12 to display VMkernel messages on the console screen.
If you are able to shutdown or move your VMs, then you can try rebooting the server by issuing the reboot command through the VI Client or alternate consoles. If not, cold-booting the server is your only option.
Lost network configurations
The problem that can occur is that you may lose part or all of your networking configurations. If this happens, you must rebuild your network by using the ESX local service console, since you will be unable to connect using the VI Client. VMware has published knowledgebase articles that detail how to rebuild your networking using the esxcfg-* service console commands and also how to verify your network settings.
Conclusion
In this tip, I have addressed a few of the most common problems that can occur with VMware ESX. In the next installment of this series, I will cover troubleshooting VirtualCenter issues.
Check the following llinks for solutions to other possible ESX problems:
Symptoms
- ESX/ESXi host is not responding to vCenter Server
- All virtual machines that are registered to the ESX or ESXi host are grayed out.
- You are unable to connect to the ESX or ESXi host directly using vSphere Client.
- The vpxd.log files residing in vCenter Server may contain events indicating an error when attempting to communicate with the ESXi host. The events always contain the words vmodl.fault.HostCommunication and may appear similar to the following examples:
[VpxLRO] -- ERROR task-internal-6433833 -- host-24499 -- vim.host.NetworkSystem.queryNetworkHint: vmodl.fault.HostCommunication:
(vmodl.fault.HostCommunication) {
dynamicType = <unset>,
faultCause = (vmodl.MethodFault) null,
msg = "",
}
[VpxdMoHost::CollectRemote] Stats collection cannot proceed because host may no longer be available or reachable: vmodl.fault.HostCommunication.
For more information on the location of the vpxd.log file
The issue may appear on multiple hosts, keep note on the opID that identifies the offending ESX/ESXi host:
2012-04-09T15:03:51.540-04:00 [29348 verbose 'Default' opID=f6a80d55] [ServerAccess] Attempting to connect to service at vc1.hostname.vmware.net:10443
For more information about this type of failure - If this issue occurs due to a communication issue between the ESXi host and the vCenter Server, but the host is still responsive to user interaction, you may see events similar to these in the /var/log/vmware/vpxa.log files:
Failed to bind heartbeat socket (-1). Using any IP.
Agent can't send heartbeats.msg size: 66, sendto() returned: Network is unreachable.
Purpose
This article provides troubleshooting steps to determine why an ESX/ESXi host is inaccessible from vCenter Server or vSphere Client.
Resolution
To determine why an ESX/ESXi host is inaccessible:
- Verify the current state of the ESX/ESXi host hardware and power. Physically go to the VMware ESX/ESXi host hardware, and make note of any lights on the face of the server hardware that may indicate the power or hardware status. For more information regarding the hardware lights, consult the hardware vendor documentation or support.
Note: Depending on the configuration of your physical environment, you may consider connecting to the physical host by using a remote hardware interface provided by your hardware vendor. For more information about how this interface interprets the condition of the hardware, consult the hardware vendor documentation or support.- If the hardware lights indicate that there is a hardware issue, consult the hardware vendor documentation or support to identify any existing hardware issues.
- If the hardware is currently turned off, turn on the hardware and see Determining why a ESX/ESXi host was powered off or restarted .
- Determine the state of the user interface of the ESX host in the physical console.
Note: Depending on the configuration of your physical environment, you may consider connecting to the physical host by using a remote application such as a Keyboard/Video/Mouse switch or a remote hardware interface provided by your hardware vendor. These interfaces are known to interfere with keyboard and mouse functionality. VMware recommends verifying the responsiveness at the local physical console prior to taking any action.- If the user interface does not respond to user interaction, see Determining why an ESX/ESXi host does not respond to user interaction at the console .
- If the user interface displays a purple diagnostic screen, see Interpreting an ESX/ESXi host purple diagnostic screen.
- Verify that DNS is configured correctly on the ESX/ESXi host. For more information, see:
- Configuring VMware ESXi Management Network from the direct console
- Clearing the DNS cache in VMware ESXi host
- Reconnecting or adding an VMware ESXi host to VMware vCenter Server fails with the error: Agent can't send heartbeats because socket address structure initialization is failing
- Identifying issues with and setting up name resolution on ESX/ESXi Server
- Determine if the ESX host responds to ping responses. For more information, see Testing network connectivity with the Ping command . If you are using ESXi, there are several menu options provided to test the management network. If the ESX host responds to user interaction, but does not respond to pings, you may have a networking issue.
- Verify that you can connect to the VMware ESX/ESXi host using vSphere Client:
- Open the vSphere Client.
- Specify the hostname or IP address of the VMware ESX/ESXi host, along with the appropriate credentials for the root user.
- Click Login.
- If you receive an error indicating that a connection failure occurred, it may indicate that the agents responsible for facilitating the vSphere API are not functioning.
- If you are able to connect to the VMware ESX/ESXI host using the vSphere Client, but it continues to show as unresponsive from vCenter Server, verify if the correct Managed IP Addressisset in vCenter Server.
- Determine if the ESX/ESXi host is rebooted.
- Physically log in to the console of the VMware ESX/ESXi host.
- If you are using ESX, log in to the service console as root.
- If you are using ESXi 4.0 and below, log in to Emergency Tech Support mode.
- If you are using ESXi 4.1 and later, log in to Tech Support mode. For more information
- Type the command uptime to view the uptime of the VMware ESX/ESXi host. If the VMware ESX/ESXi host is recently rebooted
- Physically log in to the console of the VMware ESX/ESXi host.
Related Information
High Availability
High Availability (HA) feature uses a different trigger than vCenter Server when ensuring that an ESX or ESXi is operational. The following is a brief explanation of each criteria:
- The Host connection and power state alarm is triggered as a result of a HostCommunication fault. A HostCommunication fault occurs if vCenter Server is unable to communicate to an ESX or ESXi host using the vSphere API.
- The HA isolation response is triggered as a result of an agent on the ESX or ESXi host that is unable to communicate with agents on other ESX or ESXi hosts (not the vCenter server). It must also fail to communicate with a designated isolation address (by default, it is the default gateway). If both of these conditions are met, the host performs the designated HA isolation response.
- A host that is Not Responding within vCenter Server does not always trigger a high availability isolation response. It may still be maintaining a network connection with other hosts or its isolation address and thus is not isolated .
- A host experiencing an HA isolation response is likely to appear as Not Responding within vCenter Server.
Condition 1
- If ESXi host in non responding state with the reside vms are in orphaned/disconnected mode.
- In this case we need basic checks on datastore connection/free space availability in DS.
- IDRAC/ILO to connect affected ESXi console and restart management agent at ESXI and max time its resolves the connection issues and verify ESXi to connect automatically VC.
Process to restart the ESXi management agent - Log in to ESXi using SSH as root.- Restart the ESXi host daemon and vCenter Agent services using these commands:
/etc/init.d/hostd restart
/etc/init.d/vpxa restart
- If ILO is not configured/not reachable work with Datcenter team to verify physical state of ESXi and restart ESXI using crash card console with the help of Datacenter team.
- After reboot verify ESXi connectivity with the VC and put ESXi in maintenance mode if its on the cluster.
- As part of root cause investigation verify ESXi recent task/events using web client console.
- For further analysis export affected ESXi system logs or to get it from the ESXi SSH log location:
var/log/hostd.log
- Collect Diagnostics logs with the help of below article
- Share diagnostic logs with Compute team for further analysis with VMware support. .
- If ESXi host in non responding state with reside vms availability.
- Follow above step 2, 3
- Try to reconnect ESXi with root password.
- If it failed to connect affected ESXi, (Note- in this case vms needs to be shutdown manually with the help of change and vm owners confirmation\approval.
- After the activity, ESXi should be in maintenance mode and share exported logs with Compute for further analysis with VMware support.
Symptoms
Purpose
VMware Technical Support routinely requests diagnostic information from you when a support request is handled. This diagnostic information contains product specific logs, configuration files, and data appropriate to the situation. The information is gathered using a specific script or tool for each product and can include a host support bundle from the ESXi host and vCenter Server support bundle. Data collected in a host support bundle may be considered sensitive. Additionally, as of vSphere 6.5, support bundles can include encrypted information from an ESXi host. For more information on what information is included in the support bundles
This article provides procedures for obtaining diagnostic information for a VMware ESXi/ESX host using the vm-support command line utility. For other methods of collecting the same information
The diagnostic information obtained by using this article is uploaded to VMware Technical Support. To uniquely identify your information, use the Support Request (SR) number you receive when you create the new SR.
Resolution
The command-line
vm-support utility is present on all versions of VMware ESXi/ESX, though some of the options available with the utility differ among versions.Running vm-support in a console session on ESXi/ESX hosts
The traditional way of using thevm-support command-line utility produces a gzipped tarball (.tgz file) locally on the host. The resulting file can be copied off the host using FTP, SCP, or another method.- Open a console to the ESX or ESXi host.
vm-support
Note: Additional options can be specified to customize the log bundle collection. Use thevm-support -hcommand for a list of options available on a given version of ESXi/ESX. - A compressed bundle of logs is produced and stored in a file with a
.tgzextension in one of these locations:/var/tmp//var/log/- The current working directory
- To export the log bundle to a shared vmfs datastore, use this command:
vm-support -f -w /vmfs/volumes/DATASTORE_NAME
Note: The-foption is not available in ESXi 5.x, ESXi/ESX 4.1 Update 3, and later. - The log bundle is collected and downloaded to a client, upload the logs to the SFTP/FTP site.
Streaming vm-support output from an ESXi 5.x and 6.0 host
Starting with ESXi 5.0, thevm-support command-line utility supports streaming content to the standard output. This allows to send the content over an SSH connection without saving anything locally on the ESXi host.- Enable SSH access to the ESXi shell. For more information, see Enable ESXi Shell and SSH Access with the Direct Console User Interface section in the vSphere Installation and Setup guide.
- Using a Linux or Posix client, such as the vSphere Management Assistant appliance, log in to the ESXi host and run the
vm-supportcommand with the streaming option enabled, specifying a new local file. A compressed bundle of logs is produced on the client at the specified location. For example:ssh root@ESXHostnameOrIPAddress vm-support -s > vm-support-Hostname.tgz
Note: This requires you to enter a password for the root account, and cannot be used with lockdown mode. - You can also direct the support log bundle to a desired datastore location using the same command (mentioning the destination path). For example:
ssh root@ESXHostnameOrIPAddress 'vm-support -s > /vmfs/volumes/datastorexxx/vm-support-Hostname.tgz' - After the log bundle has been collected and downloaded to a client, upload the logs to the SFTP/FTP site.
HTTP-based download of vm-support output from an ESXi 5.x and 6.0 host
Starting with ESXi 5.0, thevm-support command-line utility can be invoked via HTTP. This allows you to download content using a web browser or a command line tool like wget or curl.- Using any HTTP client, download the resource from:
https://ESXHostnameOrIPAddress/cgi-bin/vm-support.cgi
For example, download the resource using thewgetutility on a Linux or other Posix client, such as the vSphere Management Assistant appliance. A compressed bundle of logs is produced on the client at the specified location:wget https://10.11.12.13/cgi-bin/vm-support.cgi - After the log bundle is collected and downloaded to a client, upload the logs to the SFTP/FTP site.
Related Information
There have been updates for the
vm-support command-line utility for some versions of VMware ESX 2.x and 3.x. Ensure that the version of vm-support on each ESX host is up to date. The minimum version listed provides improvements required to protect the security of your data when providing support information to VMware. For more information about these security improvementsVerifying the version of the vm-support utility
Verify that your version ofvm-support is at least that listed for your version of ESXi/ESX:- ESX Server 2.5.5 requires version 1.15 or higher
- ESX Server 3.0.x requires version 1.29 or higher
- ESXi/ESX Server 3.5 requires version 1.30 or higher
- ESXi/ESX Server 4.x requires version 1.29 or higher
- ESXi Server 5.x requires version 2.0 or higher
vm-support command with no options and then cancel the collection, or run the command vm-support --version. For example:[user@esxhost]$ cd /tmp
[user@esxhost]$ vm-support
VMware ESX Server Support Script 0.94
Preparing Files: |
[Ctrl+C to cancel][user@esxhost]$ vm-support --version
vm-support v2.0
Updating the version of the vm-support utility on ESX
To update thevm-support utility on an ESX host:- Open a console to the ESX host.
- Verify the version of the
vm-supportutility installed. - Make a backup of the existing
vm-supportutility using the command:cp /usr/bin/vm-support /usr/bin/vm-support.old - Download the appropriate file for your version of VMware ESX and place it in the
/tmp/directory in the service console of the ESX system.
ESX 2.5.5
1.15http://download3.vmware.com/software/vi/
ESX255-vm-support.tar5f148445d3f02caa5e5946c389dc41ed
ESX 3.0.1
1.29http://download3.vmware.com/software/vi/
ESX301-vm-support.tgzbbb5e11ee6166775c81ab152d01068a8
ESX 3.0.2
1.29http://download3.vmware.com/software/vi/
ESX302-vm-support.tar395184ab520cbf8f8d8de5fd9b5920e4
ESX 3.0.3
1.29http://download3.vmware.com/software/vi/
ESX303-vm-support.tar798e0185ba86b49d0ed1e90deff84e6a
ESX 3.5
1.30http://download3.vmware.com/software/vi/
ESX35Classic-vm-support.tar11af1759471892c240376cdf1e7a4ad0
ESXi/ESX 4.x
1.29
vm-support is up to date for ESXi/ESX 4, no updates are available.
ESXi 5.x
2.0
vm-support is up to date for ESXi/ESX 5, no updates are available. - Run this command to extract the archived file:
tar xvzf filename.tgz - Verify that the MD5 sum of the
vm-supportfile in the attachment matches the value for your software version listed in the table above. For example:md5sum vm-support11af1759471892c240376cdf1e7a4ad0 vm-support - Copy the
vm-supportutility to the/usr/bin/directory, replacing the originalvm-supportscript.
Note: When running on an older version of ESX, the updated script might report errors about missing commands.
Reboot or Shut Down an ESX/ESXi Host
You can power off or restart (reboot) any ESX/ESXi host using the vSphere Client. You can also power off ESX hosts from the service console. Powering off a managed host disconnects it from vCenter Server, but does not remove it from the inventory.
Procedure
🛒 Recommended gear on Amazon
Disclosure: some links above are affiliate links — if you buy through them I may earn a small commission at no extra cost to you. Thanks for supporting the channel!
Great collection and thanks for sharing this info with us. Waiting for more like this.
ReplyDeleteVMware Training in Chennai
VMware Training institute in chennai
Cloud Training in Chennai
Cloud Computing Courses in Chennai
Azure Training in Chennai
Microsoft Azure Training in Chennai
DevOps course in Chennai
VMware Training in Velachery
Cloud computing Training in Anna Nagar
Vmware Esxi Down/Red/Disconnected Alerts/Issues ~ System Admin Share >>>>> Download Now
Delete>>>>> Download Full
Vmware Esxi Down/Red/Disconnected Alerts/Issues ~ System Admin Share >>>>> Download LINK
>>>>> Download Now
Vmware Esxi Down/Red/Disconnected Alerts/Issues ~ System Admin Share >>>>> Download Full
>>>>> Download LINK Id
Tired of reoccurring ESXi issue, thanks for the guide.
ReplyDeleteI have picked cheery a lot of useful clothes outdated of this amazing blog. I’d love to return greater than and over again. Thanks! ..
ReplyDeleteMicrosoft Windows Azure Training | Online Course | Certification in chennai | Microsoft Windows Azure Training | Online Course | Certification in bangalore | Microsoft Windows Azure Training | Online Course | Certification in hyderabad | Microsoft Windows Azure Training | Online Course | Certification in pune
Vmware Esxi Down/Red/Disconnected Alerts/Issues ~ System Admin Share >>>>> Download Now
ReplyDelete>>>>> Download Full
Vmware Esxi Down/Red/Disconnected Alerts/Issues ~ System Admin Share >>>>> Download LINK
>>>>> Download Now
Vmware Esxi Down/Red/Disconnected Alerts/Issues ~ System Admin Share >>>>> Download Full
>>>>> Download LINK Ag