Disclosure: some links above are affiliate links — if you buy through them I may earn a small commission at no extra cost to you. Thanks for supporting the channel!
kubernetes interview questions
kubernetes interview questions and answers
kubernetes interview questions and answers for experienced
kubernetes interview questions and answers
kubernetes interview questions and answers pdf
kubernetes latest interview questions and answers
docker kubernetes interview questions and answers
azure kubernetes interview questions and answers
kubernetes interview questions and answers for experienced
What is Kubernetes and why is it damn popular?
This is a basic interview question asked by the interviewer to check candidate’s knowledge around Kubernetes. The interviewer expects the candidate to be aware of why Kubernetes is HOT in the market and what problem does Kubernetes solve for all of us. One can begin the answer with –
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. It groups containers that make up an application into logical units for easy management and discovery.
Kubernetes is a HUGE open source project with a lot of code and functionalities. The primary responsibility of Kubernetes is container orchestration. That means making sure that all the containers that execute various workloads are scheduled to run physical or virtual machines. The containers must be packed efficiently following the constraints of the deployment environment and the cluster configuration. In addition, Kubernetes must keep an eye on all running containers and replace dead, unresponsive, or otherwise unhealthy containers.
Said that Kubernetes is rightly a platform for managing application containers across multiple hosts. It provides lots of management features for container-oriented applications, such as rolling deployment, resource, and volume management. Same as the nature of containers, it’s designed to run anywhere, so we’re able to run it on a bare metal, in our data center, on the public cloud, or even hybrid cloud.
Kubernetes considers most of the operational needs for application containers. The Top 10 Reasons why Kubernetes is so popular are as follow:
- Largest Open Source project in the world
- Great Community Support
- Robust Container deployment
- Effective Persistent storage
- Multi-Cloud Support(Hybrid Cloud)
- Container health monitoring
- Compute resource management
- Auto-scaling Feature Support
- Real-world Use cases Available
- High availability by cluster federation
Why should I use Kubernetes?
This is a bit tricky question. The intention of the interviewer is trying to understand candidate’s understanding of why should one head towards Kubernetes adoption inside the company or on the cloud.
With the advent of microservice architecture, users to individually scale key functions of an application and handle millions of customers. On top of this, technologies like Docker containers emerged in the enterprise, creating a consistent, portable, and easy way for users to quickly build these microservices. While Docker continued to thrive, managing these microservices & containers became a paramount requirement. All you need is a robust orchestration platform which can manage those containers which host your entire application. Kubernetes comes to a rescue.
Kubernetes is a robust orchestration platform which brings a number of features and which can be thought of as:
- As a container platform
- As a microservices platform
- As a portable cloud platform and a lot more.
Kubernetes provides a container-centric management environment. It orchestrates computing, networking, and storage infrastructure on behalf of user workloads. This provides much of the simplicity of Platform as a Service (PaaS) with the flexibility of Infrastructure as a Service (IaaS), and enables portability across infrastructure providers. Below are the list of features which Kubernetes provides –
- Service Discovery and load balancing: Kubernetes has a feature which assigns the containers with their own IP addresses and a unique DNS name, which can used to balance the load on them.
- Planning: Placement of the containers on the node is a crucial feature on which makes the decision based on the resources it requires and other restrictions.
- Auto Scaling: Based on the CPU usage, vertical scaling of applications is automatically triggered using the command line.
- Self Repair: This is an unique feature in the Kubernetes which will restart the container automatically when it fails. If the Node dies, then containers are replaced or re-planned on the other Nodes. You can stop the containers, if they don’t respond for the health checks.
- Storage Orchestration: This feature of Kubernetes enables the user to mount the network storage system as a local file system.
- Batch execution: Kubernetes manages both batch and CI workloads along with replacing containers that fail.
- Deployments and Automatic Rollbacks: During the configuration changes for the application hosted on the Kubernetes, progressively monitors the health to ensure that it does not terminate all the instances at once, it makes an automatic rollback only in the case of failure.
- Configuration Management and Secrets: All classifies information like keys and passwords are stored under module called Secrets in Kubernetes. These Secrets are used specially while configuring the application without having to reconstruct the image.
- Kubernetes Interview Question # 1) What is the Kubernetes?
A) Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. It groups containers that make up an application into logical units for easy management and discovery.
- Kubernetes Interview Question # 2) What is Kubernetes and how to use it?
A) Kubernetes is an open-source platform designed to automate deploying, scaling, and operating application containers. With Kubernetes, you are able to quickly and efficiently respond to customer demand: Deploy your applications quickly and predictably.
- Kubernetes Interview Question # 3) What is the meaning of Kubernetes?
A) Kubernetes (commonly referred to as “K8s”) is an open-source system for automating deployment, scaling and management of containerized applications that was originally designed by Google and donated to the Cloud Native Computing Foundation.
Docker Kubernetes Interview Questions For Experienced
- Kubernetes Interview Question # 4) What is a docker?
A) Docker container is an open source software development platform. Its main benefit is to package applications in “containers,” allowing them to be portable among any system running the Linux operating system (OS).
- Kubernetes Interview Question # 5) What is orchestration in software?
A) Application Orchestration. Application or service orchestration is the process of integrating two or more applications and/or services together to automate a process, or synchronize data in real-time. Often, point-to-point integration may be used as the path of least resistance.
- Kubernetes Questions # 6) What is a cluster in Kubernetes?
A) These master and node machines run the Kubernetes cluster orchestration system. A container cluster is the foundation of Container Engine: the Kubernetesobjects that represent your containerized applications all run on top of a cluster.
- Interview Questions on Kubernetes # 7) What is a swarm in Docker?
A) Docker Swarm is a clustering and scheduling tool for Docker containers. With Swarm, IT administrators and developers can establish and manage a cluster ofDocker nodes as a single virtual system.
- Kubernetes Openshift Interview Question # 8) What is Openshift?
A) OpenShift Online is Red Hat’s public cloud application development and hosting platform that automates the provisioning, management and scaling of applications so that you can focus on writing the code for your business, startup, or big idea.
Advanced Kubernetes Interview Questions
- Docker and Kubernetes Interview Question # 9) What is a namespace in Kubernetes?
A) Namespaces are intended for use in environments with many users spread across multiple teams, or projects. Namespaces are a way to divide cluster resources between multiple uses (via resource quota). In future versions of Kubernetes, objects in the same namespace will have the same access control policies by default.
- Kubernetes Interview Question # 10) What is a node in Kubernetes?
A) A node is a worker machine in Kubernetes, previously known as a minion. A nodemay be a VM or physical machine, depending on the cluster. Each node has the services necessary to run pods and is managed by the master components. The services on a node include Docker, kubelet and kube-proxy.
- Kubernetes Interview Question # 11) What is Docker and what does it do?
A) Docker is a tool designed to make it easier to create, deploy, and run applications by using containers. Containers allow a developer to package up an application with all of the parts it needs, such as libraries and other dependencies, and ship it all out as one package.
- Kubernetes Interview Question # 12) What is a Heapster?
A) Heapster is a cluster-wide aggregator of monitoring and event data. It supports Kubernetes natively and works on all Kubernetes setups, including our Deis Workflow setup.
- Kubernetes Interview Question # 13) Why do we use Docker?
A) Docker provides this same capability without the overhead of a virtual machine. It lets you put your environment and configuration into code and deploy it. The same Docker configuration can also be used in a variety of environments. This decouples infrastructure requirements from the application environment.
- Kubernetes Interview Question # 14) What is a docker in cloud?
A) A node is an individual Linux host used to deploy and run your applications. Docker Cloud does not provide hosting services, so all of your applications, services, and containers run on your own hosts. Your hosts can come from several different sources, including physical servers, virtual machines or cloud providers.
- Kubernetes Interview Question # 15) What is a cluster of containers?
A) A container cluster is a set of Compute Engine instances called nodes. It also creates routes for the nodes, so that containers running on the nodes can communicate with each other. The Kubernetes API server does not run on your cluster nodes. Instead, Container Engine hosts the API server.
Real-Time Kubernetes Scenario Based Interview Questions
- Kubernetes Interview Questions # 16) What is the Kubelet?
A) Kubelets run pods. The unit of execution that Kubernetes works with is the pod. A pod is a collection of containers that share some resources: they have a single IP, and can share volumes.
- Kubernetes Interview Questions # 17) What is Minikube?
A) Minikube is a tool that makes it easy to run Kubernetes locally. Minikube runs a single-node Kubernetes cluster inside a VM on your laptop for users looking to try out Kubernetes or develop with it day-to-day.
- Kubernetes Interview Questions # 18) What is Kubectl?
A) kubectl is a command line interface for running commands against Kubernetes clusters. This overview covers kubectl syntax, describes the command operations, and provides common examples. For details about each command, including all the supported flags and subcommands, see the kubectl reference documentation.
- Kubernetes Interview Questions # 19) What is the Gke?
A) Google Container Engine (GKE) is a management and orchestration system for Docker container and container clusters that run within Google’s public cloud services. Google Container Engine is based on Kubernetes, Google’s open source container management system.
- Kubernetes Interview Questions # 20) What is k8s?
A) Kubernetes, also sometimes called K8S (K – eight characters – S), is an open source orchestration framework for containerized applications that was born from the Google data centers.
- Kubernetes Interview Questions # 21) What is KUBE proxy?
A) Synopsis. The Kubernetes network proxy runs on each node. Service cluster ips and ports are currently found through Docker-links-compatible environment variables specifying ports opened by the service proxy. There is an optional addon that provides cluster DNS for these cluster IPs.
- Kubernetes Interview Questions # 22) Which process runs on Kubernetes master node?
A) Kube-apiserver process runs on Kubernetes master node.
Kubernetes Interview Questions # 23) Which process runs on Kubernetes non-master node?
A) Kube-proxy process runs on Kubernetes non-master node.
- Kubernetes Interview Questions # 24) Which process validates and configures data for the api objects like pods, services?
A) kube-apiserver process validates and configures data for the api objects.
- Kubernetes Interview Questions # 25) What is the use of kube-controller-manager?
A) kube-controller-manager embeds the core control loop which is a non-terminating loop that regulates the state of the system.
- Kubernetes Interview Questions # 26) Kubernetes objects made up of what?
A) Kubernetes objects are made up of Pod, Service and Volume.
- Kubernetes Interview Questions # 27) What are Kubernetes controllers?
A) Kubernetes controllers are Replicaset, Deployment controller.
- Kubernetes Interview Questions # 28) Where Kubernetes cluster data is stored?
A) etcd is responsible for storing Kubernetes cluster data.
- Kubernetes Interview Questions # 29) What is the role of kube-scheduler?
A) kube-scheduler is responsible for assigning a node to newly created pods.
- Kubernetes Interview Questions # 30) Which container runtimes supported by Kubernetes?
A) Kubernetes supports docker and rkt container runtimes.
- Kubernetes Interview Questions # 31) What are the components interact with Kubernetes node interface?
A) Kubectl, Kubelet, and Node Controller components interacts with Kubernetes node interface.
How do you test a manifest without actually executing it?
How do you initiate a rollback for an application?
How do you package Kubernetes applications?
What is node affinity and pod affinity?
How do you drain the traffic from a Pod during maintenance?
I have one POD and inside 2 containers are running one is Nginx and another one is wordpress So, how can access these 2 containers from the Browser with IP address?
If I have multiple containers running inside a pod, and I want to wait for a specific container to start before starting another one.
What is the impact of upgrading kubelet if we leave the pods on the worker node - will it break running pods? why?
Does the container restart When applying/updating the secret object (kubectl apply -f mysecret.yml)? If not, how is the new password applied to the database?
How should you connect an app pod with a database pod?
How to configure a default ImagePullSecret for any deployment?
volumeMounts: name: fluentd mountPath: /fluentd/etc name: varlog mountPath: /var/log name: container1 mountPath: /var/lib/docker/containers readOnly: true securityContext: privileged: true terminationGracePeriodSeconds: 30 volumes: name: varlog hostPath: path: /var/log name: container1 hostPath: path: /var/lib/docker/containers name: fluentd configMap: name: fluentd-config
When deploying you will get an error of mounting as read-only, which is effecting to fluent to read some of the mentioned sources in the configmap.how can we avoid this read-only error?
When deploying you will get an error of mounting as read-only, which is effecting to fluent to read some of the mentioned sources in the configmap.how can we avoid this read-only error?
If you have a pod that is using a ConfigMap which you updated, and you want the container to be updated with those changes, what should you do?
What is the difference between config map and secret? (Differentiate the answers as with examples)
What kind of object do you create, when your dashboard like application, queries the Kubernetes API to get some data?
How do you deploy a feature with zero downtime in Kubernetes?
How to monitor that a Pod is always running?

What is the difference between replication controllers and replica sets?
Having a Pod with two containers, can I ping each other? like using the container name?
Is there a way to make a pod to automatically come up when the host restarts?
Is there any other way to update configmap for deployment without pod restarts?
Do rolling updates declared with a deployment take effect if I manually delete pods of the replica set with kubectl delete pods or with the dashboard? Will the minimum required a number of pods be maintained?
In Kubernetes - A Pod is running 2 containers, when One container stops - another Container is still running, on this event, I want to terminate this Pod?
What happens if daemonset can be set to listen on a specific interface since the Anycast IP will be assigned to a network interface alias
Are deployments with more than one replica automatically doing rolling updates when a new deployment config is applied?
If a pod exceeds its memory "limit" what signal is sent to the process?
How do you test a manifest without actually executing it?
How do you initiate a rollback for an application?
How do you package Kubernetes applications?
What are init containers?
What is node affinity and pod affinity?
How do you drain the traffic from a Pod during maintenance?
I have one POD and inside 2 containers are running one is Nginx and another one is wordpress So, how can access these 2 containers from the Browser with IP address?
If I have multiple containers running inside a pod, and I want to wait for a specific container to start before starting another one.
What is the impact of upgrading kubelet if we leave the pods on the worker node - will it break running pods? why?
How to configure a default ImagePullSecret for any deployment?
When deploying you will get an error of mounting as read-only, which is effecting to fluent to read some of the mentioned sources in the configmap.how can we avoid this read-only error?
What is the difference between config map and secret? (Differentiate the answers as with examples)
If a node is tainted, is there a way to still schedule the pods to that node?
What kind of object do you create, when your dashboard like application, queries the Kubernetes API to get some data?
What is the difference between a Pod and a Job? Differentiate the answers as with examples)
How do you deploy a feature with zero downtime in Kubernetes?
What are the types of multi-container pod patterns? (Explain each type with examples)
What is the difference between replication controllers and replica sets?
How do you tie service to a pod or to a set of pods?
Having a Pod with two containers, can I ping each other? like using the container name?
what does kube-proxy do?
Is there a way to make a pod to automatically come up when the host restarts?
Is there any other way to update configmap for deployment without pod restarts?
what is the difference between externalIP and loadBalancerIP ?
In Kubernetes - A Pod is running 2 containers, when One container stops - another Container is still running, on this event, I want to terminate this Pod?
what is the ingress, is it something that runs as a pod or on a pod?
What happens if daemonset can be set to listen on a specific interface since the Anycast IP will be assigned to a network interface alias
Are deployments with more than one replica automatically doing rolling updates when a new deployment config is applied?
If a pod exceeds its memory "limit" what signal is sent to the process?
How Kubernetes is related to docker?
This is one of the most important question ever asked in an interview. Though we compare Docker Vs Kubernetes, it is an apple-to-orange comparison. Reason – They are both fundamentally different technologies but they work very well together, and both facilitate the management and deployment of containers in a distributed architecture.
Let me elaborate –
Docker started as a GITHUB project back in 2013(which is almost 5+ years from now). Slowly it grew massively with HUGE contributors across the world. Today it is a platform which is shipped as both – an open source as well as a commercial product. The orchestration is just a mere feature of Docker Enterprise Edition.
But if we really want to study how K8s is related to Docker, then the most preferred answer would be –
Docker CLI provides the mechanism for managing the life cycle of the containers. Where as the docker image defines the build time framework of runtime containers. CLI commands are there to start, stop, restart and perform lifecycle operations on these containers. Containers can be orchestrated and can be made to run on multiple hosts. The questions that need to be answered are how these containers are coordinated and scheduled? And how will the application running in these containers will communicate each other?
Kubernetes is the answer. Today, Kubernetes mostly uses Docker to package, instantiate, and run containerized applications. Said that there are various another container runtime available but Docker is the most popular runtime binary used by Kubernetes.
Both Kubernetes and Docker build a comprehensive standard for managing the containerized applications intelligently along with providing powerful capabilities.Docker provides a platform for building running and distributing Docker containers. Docker brings up its own clustering tool which can be used for orchestration. But Kubernetes is a orchestration platform for Docker containers which is more extensive than the Docker clustering tool, and has capacity to scale to the production level. Kubernetes is a container orchestration system for Docker containers that is more extensive than Docker Swarm and is meant to coordinate clusters of nodes at scale in production in an efficient manner. Kubernetes is a plug and play architecture for the container orchestration which provides features like high availability among the distributed nodes
How Kubernetes simplify the containerized application deployment process?
A application deployment requires , web tier , application tier and database tier . All these requirements will spawn multiple containers and these containers should communicate among each other . Kubernetes cluster will take care of the whole system and orchestrates the container needs .
Let us look at a quick WordPress application example. WordPress application consists of frontend(WordPress running on PHP and Apache) and backend(MySQL). The below YAML file can help you specify everything you will need to bring WordPress Application in a single shot:
I assume that you have n-node Kubernetes cluster running in your infrastructure. All you need is to run the below command:
kubectl create -f wordpress-deployment.yamlThat’s it. Browse to http://<IP>:80 port to open to see WordPress App up and running. Hence, we saw that how Kubernetes simplifies the application deployment.
How to Install Kubernetes?
Install below packages on all of your machines:
- kubeadm: the command to bootstrap the cluster.
- kubelet: the component that runs on all of the machines in your cluster and does things like starting pods and containers.
- kubectl: the command line util to talk to your cluster.
Note : kubeadm will not install or manage kubelet or kubectl for you, so you will need to ensure they match the version of the Kubernetes control panel you want kubeadm to install for you.
If you do not, there is a risk of a version skew occurring that can lead to unexpected, buggy behavior.
However, one minor version skew between the kubelet and the control plane is supported, but the kubelet version may never exceed the API server version. For example, kubelet running 1.7.0 should be fully compatible with a 1.8.0 API server, but not vice versa.
Below is the example for installing in Debian or Ubuntu flavours
# apt-get update && apt-get install -y apt-transport-https curl
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
# apt-get update
# apt-get install -y kubelet kubeadm kubectl
# apt-mark hold kubelet kubeadm kubectl
Configure cgroup driver used by kubelet on Master Node
When using Docker, kubeadm will automatically detect the cgroup driver for the kubelet and set it in the /var/lib/kubelet/kubeadm-flags.env file during runtime.
If you are using a different CRI, you have to modify the file /etc/default/kubelet with your cgroup-driver value, like so:
KUBELET_KUBEADM_EXTRA_ARGS=–cgroup-driver=<value>
This file will be used by kubeadm init and kubeadm join to source extra user-defined arguments for the kubelet.
Please mind, that you only have to do that if the cgroup driver of your CRI is not cgroupfs, because that is the default value in the kubelet already.
Restarting the kubelet is required:
# systemctl daemon-reload
# systemctl restart kubelet
Explain the Architecture Layers of Kubernetes?
Kubernetes can be visualized as a system built in layers, with each higher layer abstracting the complexity found in the lower levels.

Base Layer
At the base, Kubernetes makes a cluster which is a collection of hosts storage and networking resources that Kubernetes uses to run the various workloads that comprise the system . Cluster groups together a large fleet of machines into a single unit that can be consumed .
Mid Layer
The machines in the cluster are each given a role within the Kubernetes ecosystem.
The MASTER is the control plane of Kubernetes having functionalities like Authorization and authentication , RESTful API entry point. Master comprises of components, such as an API server , scheduler, and controller manager. The master is responsible for the global, cluster-level scheduling of pods and handling of events.
- The other machines in the cluster are designated as nodes:
Nodes are managed by a Kubernetes master. The nodes are worker bees of Kubernetes and do all the processing and hardwork . Each node has a container runtime , receives instructions from master node , creates / destroys container as per the workload and enroutes traffic appropriately
Application Layer/ Final Layer
Kubernetes itself is a somewhat complicated distributed system which runs on API approach .
- To run an application , a plan is submitted in yaml or json
- The master server runs the plan by examining the requirements and current state of the cluster
- All user interact with the cluster by the help of API ecosystem implemented by control plane of the master server
- Next comes the scheduler and controller-manager components that keeps the cluster functioning correctly
- In the last its the workers that will take the pain and provides the output for the job
List out the Master Server Components of Kubernetes?

Kubernetes is a combination of multiple parts working together to get the container job done and the most vital part of it is Master node . The node acts as brain to the cluster and manages the whole ecosystem .
Master connects to etcd via HTTP or HTTPS to store the data and also connects flannel to access the container application.
Worker nodes engage with master via HTTP or HTTPS to get a command and report the status.
Overlay network makes connections of their container applications. All of it will be discussed below for more in-depth
Below are the mentioned components :
etcd
- The heart of any Kubernetes cluster that implements a distributed key value store where all of the objects in a kubernetes cluster are persisted .
- It works on a algorithm which has replication techniques across servers to maintain the data stored in etcd .
- Optimistic concurrency is also used to compare-and-swap data across etcd server , when a user reads and update a value , the system checks that no other component in the system has updated the same value . This technique removes the locking mechanism that increases the server throughput .
- Another technique known as watch protocol , which accounts for changes made in key value pair in etcd directory . Its improves efficiency to the client as it wait for the changes and then react to the change without continuous polling to the server .
kube-apiserver
As the name connects , its a server that provides an HTTP- or HTTPS-based RESTful API that is allowed to have direct access to the Kubernetes cluster .
- Its a connector between all the kubernetes components and mediates all interactions between clients and the API objects stored in etcd .
- Api server database is external to it , so it is a stateless server which is replicated 3 times to implement fault-tolerance
- The APIs are exposed and managed by the server , the characteristics of those API requests must be described so that the client and server know how to communicate .
- Define API pattern where the request is defined like api paths or groups.
- Internal loops are responsible for background operations like CRD (Custom Resource Definitions) which inherently creates new paths for API requests
kube-controller-manager
The controller manager is a general service that has many responsibilities.
- Controller manager is a collection of control loops rolled up into one binary
- Manages Kubernetes nodes
- The control loops needed to implement the functionality like replica sets and deployments are run by Manager
- Creates and updates the Kubernetes internal information
- changes the current status to the desired status
kube-scheduler
- It is a simple algorithm that defines the priority to dispatch and is responsible for scheduling pods into nodes .
- is continuously scanning the API server (with watch protocol) for Pods which don’t have a nodeName and are eligible for scheduling
- Node affinity provide a simple way to guarantee that a Pod lands on a particular node
- Predicates is a concept that helps in making correct resource requirements for the pods
- Data locality
List the Node Server Components of Kubernetes ?
In Kubernetes, servers that perform work by running containers are known as nodes. Execution of jobs and reporting the status back to the master are the primary tasks on Node server .
kubelet
The main process on Kubernetes node that performs major container operations .
- The Kubelet is the node-daemon that communicates with Kubernetes master for all machines that are part of a Kubernetes cluster.
- It periodically access the controller to check and report the status of the cluster
- It merges the available CPU, disk and memory for a node into the large Kubernetes cluster.
- Communicates the state of containers back up to the api-server for control loops to observe the current state of the containers.
kube-proxy
- The kube proxy implements load-balancer networking model on each node.
- It makes the Kubernetes services locally and can do TCP and UDP forwarding.
- The kube-proxy programs the network on its node, so that network requests to the virtual IP address of a service, are in-fact routed to the endpoints which implement this service
- It finds cluster IPs via environment variables or DNS.
- Routes traffic from Pods on the machine to Pods, anywhere in the cluster

List out Kubernetes Objects and Workloads?
Kubernetes object model provides set of features to manage containers and interact with instances.
Here are the few listed different types of objects used to define workloads.
Pods : Pod is the basic unit in the Kubernetes Object Model. In Kubernetes containers are not attached to hosts directly, instead one or more containers are tightly coupled form an encapsulated object called pod.
Replication Controllers and Replication Sets : know as replication of pods. These are created from pod templates and can be horizontally scaled by controllers known as replication controllers and replication sets.
Deployments : Deployments are one of the most common workloads to directly create and manage. Deployments use replication sets as a building block, adding flexible life cycle management functionality to the mix.
Stateful Sets : Stateful sets are specialized pod controllers that offer ordering and uniqueness guarantees. For instance, stateful sets are often associated with data-oriented applications, like databases, which need access to the same volumes even if rescheduled to a new node.
Daemon Sets : Daemon sets are another specialized form of pod controller that run a copy of a pod on each node in the cluster . This is most often useful when deploying pods that help perform maintenance and provide services for the nodes themselves.
Jobs and Cron Jobs : Kubernetes uses a workload called jobs to provide a more task-based workflow where the running containers are expected to exit successfully after some time once they have completed their work. Jobs are useful if you need to perform one-off or batch processing instead of running a continuous service.
Explain the Replication Controllers and Replication Sets in Kubernetes ?
ReplicationController makes sure that a specified number of pod replicas are running at any point of time. Specifically ReplicationController ensures that a pod or set of pods are homogeneous in nature and are always up and running.
ReplicationController always maintains desired number of pods, if the number exceeds then it will terminate extra pods, or if the number decreases extra pods will be created. The pods maintained by a ReplicationController are automatically replaced if they fail, are deleted, or are terminated. Replication controllers can also perform rolling updates to roll over a set of pods to a new version one by one, minimizing the impact on application availability.
Replication sets are an iteration on the replication controller design with greater flexibility in how the controller identifies the pods it is meant to manage. Replication sets are much more advanced than ReplicationController as they have greater replica selection capabilities, but they dont have the rolling updates capabilities.
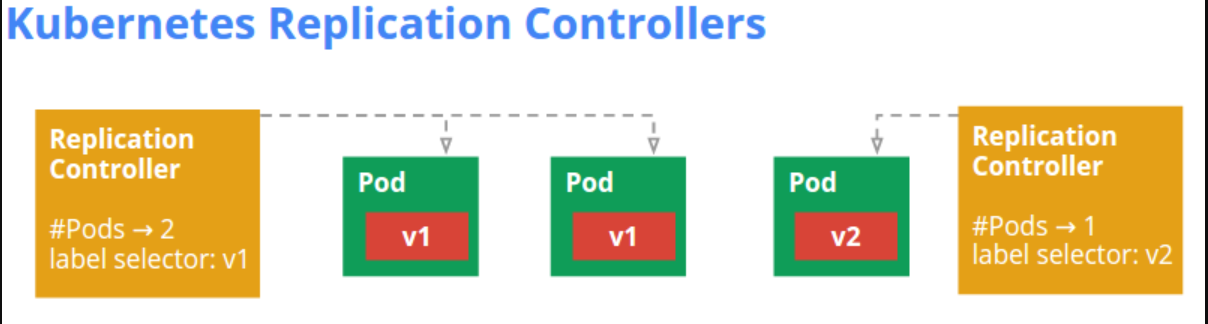
Creating a replication controller
To create replication controllers, use the subcommand run after kubectl.
// kubectl run <REPLICATION CONTROLLER NAME> --images=<IMAGE NAME> [OPTIONAL_FLAGS]
# kubectl run my-first-rc --image=nginx
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
my-first-rc my-first-rc nginx run=my-first-rc 1
Above command is creating a replication controller by image nginx .The name, my-first-rc, must be unique in all replication controllers.
Without specified number of replicas, the system will only build one pod as its default value
Explain Pods in Kubernetes Context
Pod is a single or bunch of containers that is controlled as a single application
- Containers inside the Pod operate closely together and share a common life cycle, but has to be scheduled on the same node.
- Pods are managed as a unit and share common environment wrt volume and IP address space.
- Every Pods consists of master container that satisfies of balancing the workload among the other containers that facilitate to orchestrate other related tasks.
- For example, a pod may have one container running the primary application server and a helper container pulling down files to the shared file system when changes are detected in an external repository.
- Users are recommended not to manage pods themselves, because they might miss few features specifically needed in applications.
- Users are advised to operate with the objects that use pod templates as base components and add additional functionality to them.
Use Secrets in Pods
To use Secrets inside Pods, choose to expose pods in environment variables or mount the Secrets as volumes.
In terms of accessing Secrets inside a Pod, add env section inside the container spec
// using access-token Secret inside a Pod# cat 2-7-2_env.yamlapiVersion: v1kind: Podmetadata: name: secret-pod-envspec: containers: – name: ubuntu image: ubuntu command: [“/bin/sh”, “-c”, “while : ;do echo $ACCESS_TOKEN; sleep 10; done”] env: – name: ACCESS_TOKEN valueFrom: secretKeyRef: name: access-token key: 2-7-1_access-token// create a pod# kubectl create -f 2-7-2_env.yamlpod “secret-pod-env” created
Below example, expose 2-7-1_access-token key in access-token Secret as ACCESS_TOKEN environment variable, and print it out through a while infinite loop .
// check stdout logs# kubectl logs -f secret-pod-env9S!g0U616456r
Explain stateful sets
During regular deployment process, all the instances of a pod are identical,and these stateless applications can be easily scaled up and down. In a PetSet, each pod is unique and is been assigned with unique identifier that needs to be maintained. This is technique is generally used for more stateful applications.
Example creating Stateful Set
Use the following command to get to start the creation of this StatefulSet
$ kubectl create -f abc-statefulset.yaml
Use get subcommand to see stateful sets:
$ kubectl get statefulsets$ kubectl get pods
Get the volumes the set has created and claim for each pod :
$ kubectl get pv
Explain Daemon sets
A DaemonSet is a set of pods that is run only once on a host. It’s used for host-layer features, for instance a network, host monitoring or storage plugin or other things which you would never want to run more than once on a host.
- Explain Master
Master is the central control point that provides a unified view of the cluster. There is a single master node that control multiple minions.
Master servers work together to accept user requests, determine the best ways to schedule workload containers, authenticate clients and nodes, adjust cluster-wide networking, and manage scaling and health checking responsibilities
- Explain Minions
A node is a worker machine in Kubernetes, previously known as a minion. A node may be a VM or physical machine, depending on the cluster. Each node contains the services necessary to run pods and is managed by the master components. The services on a node include the container runtime, kubelet and kube-proxy.
- ExplainVolumes and Persistent Volumes in kubernetes
A Kubernetes volume, on the other hand, the same as the Pod that encloses it. Consequently, a volume outlives any Containers that run within the Pod, and data is preserved across Container restarts. Of course, when a Pod ceases to exist, the volume will cease to exist, too. Perhaps more importantly than this, Kubernetes supports many types of volumes, and a Pod can use any number of them simultaneously.
The PersistentVolume subsystem provides an API for users and administrators that abstracts details of how storage is provided from how it is consumed. To do this we introduce two new API resources:PersistentVolume and PersistentVolumeClaim.
A PersistentVolume (PV) is a storage in the cluster that has to be provisioned by an administrator and it is a cluster resource. PVs are volume plugins like Volumes, but have a life cycle independent of any individual pod that uses the PV.
This API object captures the details of the implementation of the storage, be that NFS, iSCSI, or a cloud-provider-specific storage system.
A PersistentVolumeClaim (PVC) is a request for storage by a user. It is similar to a pod. Pods consume node resources and PVCs consume PV resources. Pods can request specific levels of resources (CPU and Memory). Claims can request specific size and access modes
Explain Labels and Annotations in kubernetes
Label in Kubernetes is meaningful tag word that can be attached to Kubernetes objects to make them as a part of a group.
Labels can be used for working on different instances for management or routing purposes.
For example, the controller-based objects use labels to mark the pods that they should operate on. Micro Services use labels to understand the structure of backend pods they should route requests to.
Labels are key-value pairs. Each unit can have more than one label, but each unit can only have one entry for each key. Key is used as an identifier, but additionally can classify objects by other criteria based on development stage, public accessibility, application version, etc activities.
Annotations attach arbitrary key-value information to an Kubernetes object. On the other hand labels should be used for meaningful information to match a pod with selection criteria, annotations contain less structured data. Annotations are a way of adding more metadata to an object that is not helpful for selection purposes.
What is a service role in kubernetes components
In Kubernetes, a service is a component that acts as a basic internal load balancer and ambassador for pods. A service groups together logical collections of pods that perform the same function to present them as a single entity.
- This allows you to deploy a service that can keep track of and route to all of the backend containers of a particular type. Internal consumers only need to know about the stable endpoint provided by the service.
- A service’s IP address remains stable regardless of changes to the pods it routes to. By deploying a service, you easily gain discoverability and can simplify your container designs.
- Any time you need to provide access to one or more pods to another application or to external consumers, you should to configure a service.
For instance, if you have a set of pods running web servers that should be accessible from the internet, a service will provide the necessary abstraction. Likewise, if your web servers need to store and retrieve data, you would want to configure an internal service to give them access to your database pods.
Explain Kubelet
Each node runs services to run containers and be managed from the master. In addition to Docker, Kubelet is another key service installed there.
It reads container manifests as YAML files that describes a pod.
Kubelet ensures that the containers defined in the pods are started and continue running.
What Is The GKE?
Google Container Engine (GKE) is a management and orchestration system for Docker container and container clusters that run within Google’s public cloud services. Google Container Engine is based on Kubernetes, Google’s open source container management system.
Kubernetes Networking – ( Intermediate Level )
What happens when a master fails? What happens when a worker fails?
Kubernetes is designed to be resilient to any individual node failure, master or worker. When a master fails the nodes of the cluster will keep operating, but there can be no changes including pod creation or service member changes until the master is available. When a worker fails, the master stops receiving messages from the worker. If the master does not receive status updates from the worker the node will be marked as NotReady. If a node is NotReady for 5 minutes, the master reschedules all pods that were running on the dead node to other available nodes.
How does DNS work in Kubernetes?
There is a DNS server called skydns which runs in a pod in the cluster, in the kube-system namespace. That DNS server reads from etcd and can serve up dns entries for Kubernetes services to all pods. You can reach any service with the name <service>.<namespace>.svc.cluster.local. The resolver automatically searches <namespace>.svc.cluster.local dns so that you should be able to call one service to another in the same namespace with just <service>.
How do you build a High Availability (HA) cluster?
The only stateful part of a Kubernetes cluster is the etcd. The master server runs the controller manager, scheduler, and the API server and can be run as replicas. The controller manager and scheduler in the master servers use a leader election system, so only one controller manager and scheduler is active for the cluster at any time. So an HA cluster generally consists of an etcd cluster of 3+ nodes and multiple master nodes.
Add nodes in a HA cluster in kubernetes
Once the masters are ready, nodes can be added into the system. The node should be finished with the prerequisite configuration as a worker node in the kubeadm cluster.
Need to start kublet
$ sudo systemctl enable kubelet && sudo systemctl start kubelet
Run the join command as below . However, please change the master IP to the load balancer one:
// join command $ sudo kubeadm join –token <CUSTOM_TOKEN> <LOAD_BALANCER_IP>:6443 –discovery-token-ca-cert-hash sha256:<HEX_STRING>
Then go to the first master or second master to check the nodes’ status:
// see the node is added$ kubectl get nodesNAME STATUS ROLES AGE VERSIONmaster01 Ready master 4h v1.10.2master02 Ready master 3h v1.10.2node01 Ready <none> 22s v1.10.2
How do I determine the status of a Deployment?
Use kubectl get deployment <deployment>. If the DESIRED, CURRENT, UP-TO-DATE are all equal, then the Deployment has completed.
How do I update all my pods if the image changed but the tag is the same?
Make sure your imagePullPolicy is set to Always(this is the default). That means when a pod is deleted, a new pod will ensure it has the current version of the image. Then refresh all your pods.
The simplest way to refresh all your pods is to just delete them and they will be recreated with the latest image. This immediately destroys all your pods which will cause a service outage. Do this with kubectl delete pod -l <name>=<value> where name and value are the label selectors your deployment uses.
A better way is to edit your deployment and modify the deployment pod spec to add or change any annotation. This will cause all your pods to be deleted and rescheduled, but this method will also obey your rollingUpdate strategy, meaning no downtime assuming your rollingUpdate strategy already behaves properly. Setting a timestamp or a version number is convenient, but any change to pod annotations will cause a rolling update. For a deployment named nginx, this can be done with:
PATCH='{“spec”:{“template”:{“metadata”:{“annotations”:{“timestamp”:”‘$(date)'”}}}}}’
kubectl patch deployment nginx -p “$PATCH”
It is considered bad practice to rely on the :latest docker image tag in your deployments, because using :latest there is no way to rollback or specify what version of your image to use. It’s better to update the deployment with an exact version of the image and use –record so that you can use kubectl rollout undo deployment <deployment> or other commands to manage rollouts.
How do I debug a Pending pod?
A Pending pod is one that cannot be scheduled onto a node. Doing a kubectl describe pod <pod> will usually tell you why. kubectl logs <pod> can also be helpful. There are several common reasons for pods stuck in Pending:
The pod is requesting more resources than are available, a pod has set a request for an amount of CPU or memory that is not available anywhere on any node. eg. requesting a 8 CPU cores when all your nodes only have 4 CPU cores. Doing a kubectl describe node <node> on each node will also show already requested resources. ** There are taints that prevent a pod from scheduling on your nodes. ** The nodes have been marked unschedulable with kubectl cordon ** There are no Ready nodes. kubectl get nodes will display the status of all nodes.
Example:
$ kubectl get po requests-pod-3NAME READY STATUS RESTARTS AGErequests-pod-3 0/1 Pending 0 4m
Examining why a pod is stuck at Pending with kubectl describe pod
$ kubectl describe po requests-pod-3Name: requests-pod-3Namespace: defaultNode: /
…Conditions: Type Status PodScheduled False …Events:… Warning FailedScheduling No nodes are available that match all of the following predicates:: Insufficient cpu (1).
What is KUBE proxy?
The Kubernetes network proxy runs on each node. Service cluster ips and ports are currently found through Docker-links-compatible environment variables specifying ports opened by the service proxy. There is an optional addon that provides cluster DNS for these cluster IPs.
How do I debug a Pending pod?
A Pending pod is one that cannot be scheduled onto a node. Doing a kubectl describe pod <pod> will usually tell you why. kubectl logs <pod> can also be helpful. There are several common reasons for pods stuck in Pending:
** The pod is requesting more resources than are available, a pod has set a request for an amount of CPU or memory that is not available anywhere on any node. eg. requesting a 8 CPU cores when all your nodes only have 4 CPU cores. Doing a kubectl describe node <node> on each node will also show already requested resources. ** There are taints that prevent a pod from scheduling on your nodes. ** The nodes have been marked unschedulable with kubectl cordon ** There are no Ready nodes. kubectl get nodes will display the status of all nodes.
How do I rollback the Deployment?
If you apply a change to a Deployment with the –record flag then Kubernetes stores the previous Deployment in its history. The kubectl rollout history deployment <deployment> command will show prior Deployments. The last Deployment can be restored with the kubectl rollout undo deployment <deployment> command. In progress Deployments can also be paused and resumed.
When a new version of a Deployment is applied, a new ReplicaSet object is created which is slowly scaled up while the old ReplicaSet is scaled down. You can look at each ReplicaSet that has been rolled out with kubectl get replicaset. Each ReplicaSet is named with the format -, so you can also do kubectl describe replicaset <replicaset>.
What is an Ingress Controller?
An Ingress Controller is a pod that can act as an inbound traffic handler. It is a HTTP reverse proxy that is implemented as a somewhat customizable nginx. Among the features are HTTP path and service based routing and SSL termination.
Kubernetes – Expert Level
How do I expose a service to a host outside the cluster?
There are two ways:
- Set the service type to NodePort. This makes every node in the cluster listen on the specified NodePort, then any node will forward traffic from that NodePort to a random pod in the service.
- Set the service type to Load Balancer. This provisions a NodePort as above, but then does an additional step to provision a load balancer in your cloud(AWS or GKE) automatically. In AWS it also modifies the Auto-Scaling Group of the cluster so all nodes of that ASG are added to the ELB.
How does a Load Balancer service work?
A Load Balancer by default is set up as a TCP Load Balancer with your cloud provider (AWS or GKE). There is no support in bare metal or OpenStack for Load Balancer types. The Kubernetes controller manager provisions a load balancer in your cloud and puts all of your Kubernetes nodes into the load balancer. Because each node is assumed to be running kube-proxy it should be listening on the appropriate NodePort and then it can forward incoming requests to a pod that is available for the service.
Because the LoadBalancer type is by default TCP, not HTTP many higher level features of a LoadBalancer are not available. For instance health checking from the LoadBalancer to the node is done with a TCP check. HTTP X-Forwarded-For information is not available, though it is possible to use proxy protocol in AWS.
Is it possible to force the pod to run on a specific node?
Kubernetes by default does attempt node anti-affinity, but it is not a hard requirement, it is best effort, but will schedule multiple pods on the same node if that is the only way.
You can constrain a pod to only be able to run on particular nodes or to prefer to run on particular nodes. There are several ways to do this, and they all use label selectors to make the selection. Generally such constraints are unnecessary, as the scheduler will automatically do a reasonable placement (e.g. spread your pods across nodes, not place the pod on a node with insufficient free resources, etc.) but there are some circumstances where you may want more control on a node where a pod lands, e.g. to ensure that a pod ends up on a machine with an SSD attached to it, or to co-locate pods from two different services that communicate a lot into the same availability zone.
How do I get all the pods on a node?
You can use the following command to get all the pods on a node in kubernetes Cluster –
$ kubectl get po –all-namespaces -o jsonpath='{range .items[?(@.spec.nodeName ==”nodename”)]}{.metadata.name}{“\n”}{end}’
Can pods mount NFS volumes?
Yes, there’s an example here of both an NFS client and server running within pods in the cluster:
Example:
Configuring NFS Server
Define NFS server pod and NFS service:
$ kubectl create -f nfs-server-pod.yaml
$ kubectl create -f nfs-server-service.yaml
The server exports /mnt/data directory, which contains dummy index.html. Wait until the pod is running!
Configuring NFS Client
See WEB server pod, which runs a simple web server serving data from the NFS. The pod assumes your DNS is set up and the NFS service is reachable as nfs-server.default.kube.local. Edit the yaml file to supply another name or directly its IP address (use kubectl get services to get it).
Finally, define the pod:
$ kubectl create -f web-pod.yaml
Now the pod serves index.html from the NFS server:
$ curl http://<the container IP address>/
Hello World!
Is it possible to route traffic from outside the Kubernetes cluster directly to pods?
Yes. But one major downside of that is that ClusterIPs are implemented as iptables rules on cluster clients, so you’d lose the ability to see Cluster IPs and service changes. Because the iptables are managed by kube-proxy you could do this by running a kube-proxy, which is similar to just joining the cluster. You could make all your services Headless(ClusterIP = None), this would give your external servers the ability to talk directly to services if they could use the kubernetes dns. Headless services don’t use ClusterIPs, but instead just create a DNS A record for all pods in the service. kube-dns is run inside the cluster as a ClusterIP, so there’s a chicken and egg problem with DNS you would have to deal with.
Why is my pod showing “pending” status?
Pending usually means that a pod cannot be scheduled, because of a resource limitation, most commonly the cluster can’t find a node which has the available CPU and memory requests to satisfy the scheduler. kubectl describe pod <podid> will show the reason why the pod can’t be scheduled. Pods can remain in the Pending state indefinitely until the resources are available or until you reduce the number of required replicas.
What monitoring and metrics tools do people use for Kubernetes?
Heapster is included and its metrics are how Kubernetes measures CPU and memory in order to use horizontal pod autoscaling (HPA). Heapster can be queried directly with its REST API. Prometheus is also more full featured and popular.
How can containers within a pod communicate with each other?
Containers within a pod share networking space and can reach other on localhost. For instance, if you have two containers within a pod, a MySQL container running on port 3306, and a PHP container running on port 80, the PHP container could access the MySQL one through localhost:3306.
How do I configure credentials to download images from a private docker registry?
Create a special secret in a your namespace that provides the registry and credentials to authenticate with. Then use that secret in the spec.imagePullSecrets field of your pod specification. Private registries may require keys to read images from them. Credentials can be provided in several ways:
- Using Google Container Registry
- Per-cluster
- automatically configured on Google Compute Engine or Google Kubernetes Engine
- all pods can read the project’s private registry
- Using AWS EC2 Container Registry (ECR)
- use IAM roles and policies to control access to ECR repositories
- automatically refreshes ECR login credentials
- Using Azure Container Registry (ACR)
- Configuring Nodes to Authenticate to a Private Registry
- all pods can read any configured private registries
- requires node configuration by cluster administrator
- Pre-pulling Images
- all pods can use any images cached on a node
- requires root access to all nodes to setup
- Specifying ImagePullSecrets on a Pod
- only pods which provide own keys can access the private registry.
Explain the concept of Taints and Tolerations
Taints and tolerations work together to ensure that pods are not scheduled onto inappropriate nodes. One or more taints are applied to a node; this marks that the node should not accept any pods that do not tolerate the taints. Tolerations are applied to pods, and allow (but do not require) the pods to schedule onto nodes with matching taints.
You add a taint to a node using kubectl taint. For example,
kubectl taint nodes node1 key=value:NoSchedule
places a taint on node node1. The taint has key key, value value, and taint effect NoSchedule. This means that no pod will be able to schedule onto node1 unless it has a matching toleration.
To remove the taint added by the command above, you can run:
kubectl taint nodes node1 key:NoSchedule-
You specify a toleration for a pod in the PodSpec. Both of the following tolerations “match” the taint created by the kubectl taint line above, and thus a pod with either toleration would be able to schedule onto node1:
tolerations:
– key: “key”
operator: “Equal”
value: “value”
effect: “NoSchedule”
tolerations:
– key: “key”
operator: “Exists”
effect: “NoSchedule”
A toleration “matches” a taint if the keys are the same and the effects are the same, and:
- the operator is Exists (in which case no value should be specified), or
- the operator is Equal and the values are equal
Operator defaults to Equal if not specified.
Explain the role of Secrets in Kubernetes
A Secret is an object that contains a small amount of sensitive data such as a password, a token, or a key. Such information might otherwise be put in a Pod specification or in an image; putting it in a Secret object allows for more control over how it is used, and reduces the risk of accidental exposure.
Objects of type secret are intended to hold sensitive information, such as passwords, OAuth tokens, and ssh keys. Putting this information in a secret is safer and more flexible than putting it verbatim in a pod definition or in a docker image.
Users can create secrets, and the system also creates some secrets.
To use a secret, a pod needs to reference the secret. A secret can be used with a pod in two ways: as files in a volume mounted on one or more of its containers, or used by kubelet when pulling images for the pod.
How can we priortize pods and preempt them.
Pods can have priority. Priority indicates the importance of a Pod relative to other Pods. If a Pod cannot be scheduled, the scheduler tries to preempt (evict) lower priority Pods to make scheduling of the pending Pod possible.
In Kubernetes 1.9 and later, Priority also affects scheduling order of Pods and out-of-resource eviction ordering on the Node.
Pod priority and preemption are moved to beta since Kubernetes 1.11 and are enabled by default in this release and later.
In Kubernetes versions where Pod priority and preemption is still an alpha-level feature, you need to explicitly enable it. To use these features in the older versions of Kubernetes, follow the instructions in the documentation for your Kubernetes version, by going to the documentation archive version for your Kubernetes version.
A PriorityClass is a non-namespaced object that defines a mapping from a priority class name to the integer value of the priority. The name is specified in the name field of the PriorityClass object’s metadata. The value is specified in the required value field. The higher the value, the higher the priority.
A PriorityClass object can have any 32-bit integer value smaller than or equal to 1 billion. Larger numbers are reserved for critical system Pods that should not normally be preempted or evicted. A cluster admin should create one PriorityClass object for each such mapping that they want.
PriorityClass also has two optional fields: globalDefault and description. The globalDefault field indicates that the value of this PriorityClass should be used for Pods without a priorityClassName. Only one PriorityClass with globalDefault set to true can exist in the system. If there is no PriorityClass with globalDefault set, the priority of Pods with no priorityClassName is zero.
Explain the Kubernetes model for connecting containers
Now that you have a continuously running, replicated application you can expose it on a network. Before discussing the Kubernetes approach to networking, it is worthwhile to contrast it with the “normal” way networking works with Docker.
By default, Docker uses host-private networking, so containers can talk to other containers only if they are on the same machine. In order for Docker containers to communicate across nodes, there must be allocated ports on the machine’s own IP address, which are then forwarded or proxied to the containers. This obviously means that containers must either coordinate which ports they use very carefully or ports must be allocated dynamically.
Coordinating ports across multiple developers is very difficult to do at scale and exposes users to cluster-level issues outside of their control. Kubernetes assumes that pods can communicate with other pods, regardless of which host they land on. We give every pod its own cluster-private-IP address so you do not need to explicitly create links between pods or mapping container ports to host ports. This means that containers within a Pod can all reach each other’s ports on localhost, and all pods in a cluster can see each other without NAT. The rest of this document will elaborate on how you can run reliable services on such a networking model.
Explain the concept of Storage Classes
A StorageClass provides a way for administrators to describe the “classes” of storage they offer. Different classes might map to quality-of-service levels, or to backup policies, or to arbitrary policies determined by the cluster administrators. Kubernetes itself is unopinionated about what classes represent. This concept is sometimes called “profiles” in other storage systems.
Each StorageClass contains the fields provisioner, parameters, and reclaimPolicy, which are used when a PersistentVolume belonging to the class needs to be dynamically provisioned.
What are the volumes per node limits for each Cloud providers
The Kubernetes scheduler has default limits on the number of volumes that can be attached to a node:
Cloud service
Maximum volumes per node
Amazon Elastic Block Store (EBS)
39
Google Persistent Disk
16
Microsoft Azure Disk Storage
16
How many types of Container Hooks are available, and explain each one of them
The hooks enable Containers to be aware of events in their management lifecycle and run code implemented in a handler when the corresponding lifecycle hook is executed.
There are two hooks that are exposed to Containers:
PostStart
This hook executes immediately after a container is created. However, there is no guarantee that the hook will execute before the container ENTRYPOINT. No parameters are passed to the handler.
PreStop
This hook is called immediately before a container is terminated. It is blocking, meaning it is synchronous, so it must complete before the call to delete the container can be sent. No parameters are passed to the handler.
What is a Resource Quota and Why we need them.
A resource quota, defined by a ResourceQuota object, provides constraints that limit aggregate resource consumption per namespace. It can limit the quantity of objects that can be created in a namespace by type, as well as the total amount of compute resources that may be consumed by resources in that project.
Resource quotas work like this:
- Different teams work in different namespaces. Currently this is voluntary, but support for making this mandatory via ACLs is planned.
- The administrator creates one or more ResourceQuotas for each namespace.
- Users create resources (pods, services, etc.) in the namespace, and the quota system tracks usage to ensure it does not exceed hard resource limits defined in a ResourceQuota.
- If creating or updating a resource violates a quota constraint, the request will fail with HTTP status code 403 FORBIDDEN with a message explaining the constraint that would have been violated.
- If quota is enabled in a namespace for compute resources like cpu and memory, users must specify requests or limits for those values; otherwise, the quota system may reject pod creation. Hint: Use the LimitRanger admission controller to force defaults for pods that make no compute resource requirements. See the walkthrough for an example of how to avoid this problem.
49. What is a Pod Security Policy and How to enable one?
A Pod Security Policy is a cluster-level resource that controls security sensitive aspects of the pod specification. The PodSecurityPolicy objects define a set of conditions that a pod must run with in order to be accepted into the system, as well as defaults for the related fields.
Pod security policy control is implemented as an optional (but recommended) admission controller. PodSecurityPolicies are enforced by enabling the admission controller, but doing so without authorizing any policies will prevent any pods from being created in the cluster.
Since the pod security policy API (policy/v1beta1/podsecuritypolicy) is enabled independently of the admission controller, for existing clusters it is recommended that policies are added and authorized before enabling the admission controller.
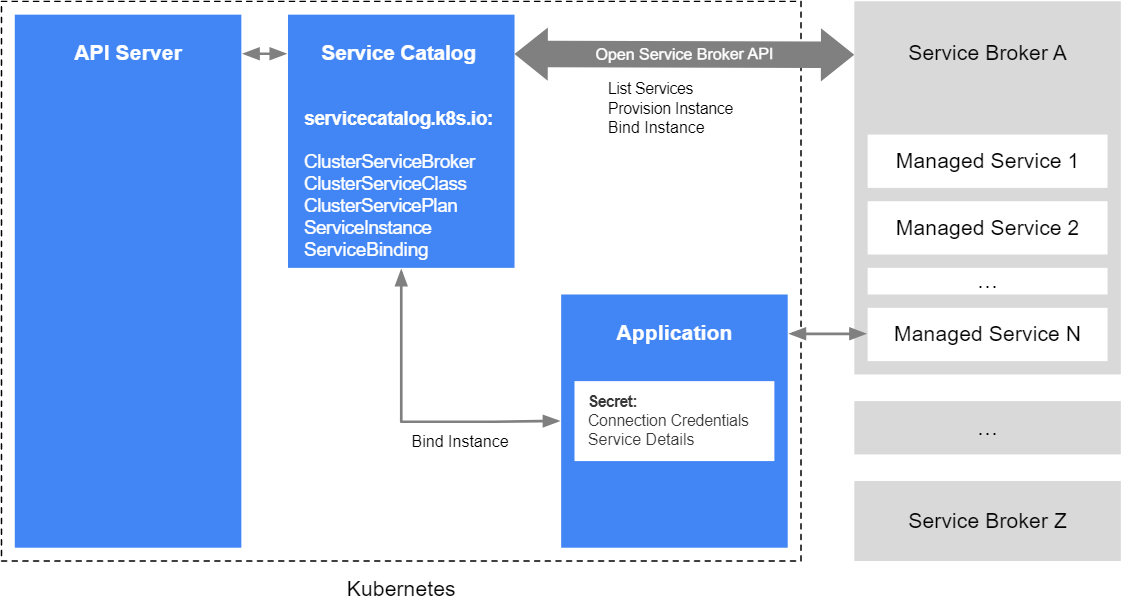
50. Explain the Service Catalog along with its Architecture
Service Catalog is an extension API that enables applications running in Kubernetes clusters to easily use external managed software offerings, such as a datastore service offered by a cloud provider.
It provides a way to list, provision, and bind with external Managed Services from Service Brokers without needing detailed knowledge about how those services are created or managed.
Using Service Catalog, a cluster operator can browse the list of managed services offered by a service broker, provision an instance of a managed service, and bind with it to make it available to an application in the Kubernetes cluster.
Service Catalog uses the Open service broker API to communicate with service brokers, acting as an intermediary for the Kubernetes API Server to negotiate the initial provisioning and retrieve the credentials necessary for the application to use a managed service.
It is implemented as an extension API server and a controller, using etcd for storage. It also uses the aggregation layer available in Kubernetes 1.7+ to present its API.
How is Kubernetes different from Docker Swarm?
Features
Kubernetes
Docker Swarm
Installation & Cluster Config
Setup is very complicated, but once installed cluster is robust.
Installation is very simple, but the cluster is not robust.
GUI
GUI is the Kubernetes Dashboard.
There is no GUI.
Scalability
Highly scalable and scales fast.
Highly scalable and scales 5x faster than Kubernetes.
Auto-scaling
Kubernetes can do auto-scaling.
Docker swarm cannot do auto-scaling.
Load Balancing
Manual intervention needed for load balancing traffic between different containers and pods.
Docker swarm does auto load balancing of traffic between containers in the cluster.
Rolling Updates & Rollbacks
Can deploy rolling updates and does automatic rollbacks.
Can deploy rolling updates, but not automatic rollback.
DATA Volumes
Can share storage volumes only with the other containers in the same pod.
Can share storage volumes with any other container.
Logging & Monitoring
In-built tools for logging and monitoring.
3rd party tools like ELK stack should be used for logging and monitoring.
What is Kubernetes?
What is Kubernetes – Kubernetes Interview Questions
Kubernetes is an open-source container management tool which holds the responsibilities of container deployment, scaling & descaling of containers & load balancing. Being the Google’s brainchild, it offers excellent community and works brilliantly with all the cloud providers. So, we can say that Kubernetes is not a containerization platform, but it is a multi-container management solution.
How is Kubernetes related to Docker?
It’s a known fact that Docker provides the lifecycle management of containers and a Docker image builds the runtime containers. But, since these individual containers have to communicate, Kubernetes is used. So, Docker builds the containers and these containers communicate with each other via Kubernetes. So, containers running on multiple hosts can be manually linked and orchestrated using Kubernetes.
What is the difference between deploying applications on hosts and containers?
Deploying Applications On Host vs Containers – Kubernetes Interview Questions
Refer to the above diagram. The left side architecture represents deploying applications on hosts. So, this kind of architecture will have an operating system and then the operating system will have a kernel which will have various libraries installed on the operating system needed for the application. So, in this kind of framework you can have n number of applications and all the applications will share the libraries present in that operating system whereas while deploying applications in containers the architecture is a little different.
This kind of architecture will have a kernel and that is the only thing that’s going to be the only thing common between all the applications. So, if there’s a particular application which needs Java then that particular application we’ll get access to Java and if there’s another application which needs Python then only that particular application will have access to Python.
The individual blocks that you can see on the right side of the diagram are basically containerized and these are isolated from other applications. So, the applications have the necessary libraries and binaries isolated from the rest of the system, and cannot be encroached by any other application.
What is Container Orchestration?
Consider a scenario where you have 5-6 microservices for an application. Now, these microservices are put in individual containers, but won’t be able to communicate without container orchestration. So, as orchestration means the amalgamation of all instruments playing together in harmony in music, similarly container orchestration means all the services in individual containers working together to fulfill the needs of a single server.
What is the need for Container Orchestration?
Consider you have 5-6 microservices for a single application performing various tasks, and all these microservices are put inside containers. Now, to make sure that these containers communicate with each other we need container orchestration.
Challenges Without Container Orchestration – Kubernetes Interview Questions
As you can see in the above diagram, there were also many challenges that came into place without the use of container orchestration. So, to overcome these challenges the container orchestration came into place.
What are the features of Kubernetes?
The features of Kubernetes, are as follows:
Features Of Kubernetes – Kubernetes Interview Questions
How does Kubernetes simplify containerized Deployment?
As a typical application would have a cluster of containers running across multiple hosts, all these containers would need to talk to each other. So, to do this you need something big that would load balance, scale & monitor the containers. Since Kubernetes is cloud-agnostic and can run on any public/private providers it must be your choice simplify containerized deployment.
What do you know about clusters in Kubernetes?
The fundamental behind Kubernetes is that we can enforce the desired state management, by which I mean that we can feed the cluster services of a specific configuration, and it will be up to the cluster services to go out and run that configuration in the infrastructure.
Representation Of Kubernetes Cluster – Kubernetes Interview Questions
So, as you can see in the above diagram, the deployment file will have all the configurations required to be fed into the cluster services. Now, the deployment file will be fed to the API and then it will be up to the cluster services to figure out how to schedule these pods in the environment and make sure that the right number of pods are running.
So, the API which sits in front of services, the worker nodes & the Kubelet process that the nodes run, all together make up the Kubernetes Cluster.
What is Google Container Engine?
Google Container Engine (GKE) is an open source management platform for Docker containers and the clusters. This Kubernetes based engine supports only those clusters which run within the Google’s public cloud services.
What is Heapster?
Heapster is a cluster-wide aggregator of data provided by Kubelet running on each node. This container management tool is supported natively on Kubernetes cluster and runs as a pod, just like any other pod in the cluster. So, it basically discovers all nodes in the cluster and queries usage information from the Kubernetes nodes in the cluster, via on-machine Kubernetes agent.
Q12. What is Minikube?
Minikube is a tool that makes it easy to run Kubernetes locally. This runs a single-node Kubernetes cluster inside a virtual machine.
What is Kubectl?
Kubectl is the platform using which you can pass commands to the cluster. So, it basically provides the CLI to run commands against the Kubernetes cluster with various ways to create and manage the Kubernetes component.
What is Kubelet?
This is an agent service which runs on each node and enables the slave to communicate with the master. So, Kubelet works on the description of containers provided to it in the PodSpec and makes sure that the containers described in the PodSpec are healthy and running.
What do you understand by a node in Kubernetes?
Fig 6: Node In Kubernetes – Kubernetes Interview Questions
Interested in learning Kubernetes?
Architecture-Based Kubernetes Interview Questions
This section of questions will deal with the questions related to the architecture of Kubernetes.
Q1. What are the different components of Kubernetes Architecture?
The Kubernetes Architecture has mainly 2 components – the master node and the worker node. As you can see in the below diagram, the master and the worker nodes have many inbuilt components within them. The master node has the kube-controller-manager, kube-apiserver, kube-scheduler, etcd. Whereas the worker node has kubelet and kube-proxy running on each node.
Architecture Of Kubernetes – Kubernetes Interview Questions
What do you understand by Kube-proxy?
Kube-proxy can run on each and every node and can do simple TCP/UDP packet forwarding across backend network service. So basically, it is a network proxy which reflects the services as configured in Kubernetes API on each node. So, the Docker-linkable compatible environment variables provide the cluster IPs and ports which are opened by proxy.
Can you brief on the working of the master node in Kubernetes?
Kubernetes master controls the nodes and inside the nodes the containers are present. Now, these individual containers are contained inside pods and inside each pod, you can have a various number of containers based upon the configuration and requirements. So, if the pods have to be deployed, then they can either be deployed using user interface or command line interface. Then, these pods are scheduled on the nodes and based on the resource requirements, the pods are allocated to these nodes. The kube-apiserver makes sure that there is communication established between the Kubernetes node and the master components.
What is the role of kube-apiserver and kube-scheduler?
The kube – apiserver follows the scale-out architecture and, is the front-end of the master node control panel. This exposes all the APIs of the Kubernetes Master node components and is responsible for establishing communication between Kubernetes Node and the Kubernetes master components.
The kube-scheduler is responsible for distribution and management of workload on the worker nodes. So, it selects the most suitable node to run the unscheduled pod based on resource requirement and keeps a track of resource utilization. It makes sure that the workload is not scheduled on nodes which are already full.
Can you brief about the Kubernetes controller manager?
Multiple controller processes run on the master node but are compiled together to run as a single process which is the Kubernetes Controller Manager. So, Controller Manager is a daemon that embeds controllers and does namespace creation and garbage collection. It owns the responsibility and communicates with the API server to manage the end-points.
So, the different types of controller manager running on the master node are :
Types Of Controllers – Kubernetes Interview Questions
What is ETCD?
Etcd is written in Go programming language and is a distributed key-value store used for coordinating between distributed work. So, Etcd stores the configuration data of the Kubernetes cluster, representing the state of the cluster at any given point in time.
What are the different types of services in Kubernetes?
The following are the different types of services used:

Types Of Services – Kubernetes Interview Questions
What do you understand by load balancer in Kubernetes?
A load balancer is one of the most common and standard ways of exposing service. There are two types of load balancer used based on the working environment i.e. either the Internal Load Balancer or the External Load Balancer. The Internal Load Balancer automatically balances load and allocates the pods with the required configuration whereas the External Load Balancer directs the traffic from the external load to the backend pods.
What is Ingress network, and how does it work?
Ingress network is a collection of rules that acts as an entry point to the Kubernetes cluster. This allows inbound connections, which can be configured to give services externally through reachable URLs, load balance traffic, or by offering name-based virtual hosting. So, Ingress is an API object that manages external access to the services in a cluster, usually by HTTP and is the most powerful way of exposing service.
Now, let me explain to you the working of Ingress network with an example.
There are 2 nodes having the pod and root network namespaces with a Linux bridge. In addition to this, there is also a new virtual ethernet device called flannel0(network plugin) added to the root network.
Now, suppose we want the packet to flow from pod1 to pod 4. Refer to the below diagram.

Working Of Ingress Network – Kubernetes Interview Questions
-
So, the packet leaves pod1’s network at eth0 and enters the root network at veth0.
-
Then it is passed on to cbr0, which makes the ARP request to find the destination and it is found out that nobody on this node has the destination IP address.
-
So, the bridge sends the packet to flannel0 as the node’s route table is configured with flannel0.
-
Now, the flannel daemon talks to the API server of Kubernetes to know all the pod IPs and their respective nodes to create mappings for pods IPs to node IPs.
-
The network plugin wraps this packet in a UDP packet with extra headers changing the source and destination IP’s to their respective nodes and sends this packet out via eth0.
-
Now, since the route table already knows how to route traffic between nodes, it sends the packet to the destination node2.
-
The packet arrives at eth0 of node2 and goes back to flannel0 to de-capsulate and emits it back in the root network namespace.
-
Again, the packet is forwarded to the Linux bridge to make an ARP request to find out the IP that belongs to veth1.
-
The packet finally crosses the root network and reaches the destination Pod4.
What do you understand by Cloud controller manager?
The Cloud Controller Manager is responsible for persistent storage, network routing, abstracting the cloud-specific code from the core Kubernetes specific code, and managing the communication with the underlying cloud services. It might be split out into several different containers depending on which cloud platform you are running on and then it enables the cloud vendors and Kubernetes code to be developed without any inter-dependency. So, the cloud vendor develops their code and connects with the Kubernetes cloud-controller-manager while running the Kubernetes.
The various types of cloud controller manager are as follows:
 What is Container resource monitoring?
What is Container resource monitoring?
As for users, it is really important to understand the performance of the application and resource utilization at all the different abstraction layer, Kubernetes factored the management of the cluster by creating abstraction at different levels like container, pods, services and whole cluster. Now, each level can be monitored and this is nothing but Container resource monitoring.
The various container resource monitoring tools are as follows:

Container Resource Monitoring Tools – Kubernetes Interview Questions
What is the difference between a replica set and replication controller?
Replica Set and Replication Controller do almost the same thing. Both of them ensure that a specified number of pod replicas are running at any given time. The difference comes with the usage of selectors to replicate pods. Replica Set use Set-Based selectors while replication controllers use Equity-Based selectors.
-
Equity-Based Selectors: This type of selector allows filtering by label key and values. So, in layman terms, the equity-based selector will only look for the pods which will have the exact same phrase as that of the label.
Example: Suppose your label key says app=nginx, then, with this selector, you can only look for those pods with label app equal to nginx.
-
Selector-Based Selectors: This type of selector allows filtering keys according to a set of values. So, in other words, the selector based selector will look for pods whose label has been mentioned in the set.
Example: Say your label key says app in (nginx, NPS, Apache). Then, with this selector, if your app is equal to any of nginx, NPS, or Apache, then the selector will take it as a true result.
What is a Headless Service?
Headless Service is similar to that of a ‘Normal’ services but does not have a Cluster IP. This service enables you to directly reach the pods without the need of accessing it through a proxy.
What are the best security measures that you can take while using Kubernetes?
The following are the best security measures that you can follow while using Kubernetes:

Best Security Measures – Kubernetes Interview Questions
What are federated clusters?
Multiple Kubernetes clusters can be managed as a single cluster with the help of federated clusters. So, you can create multiple Kubernetes clusters within a data center/cloud and use federation to control/manage them all at one place.
The federated clusters can achieve this by doing the following two things. Refer to the below diagram.

Federated Clusters – Kubernetes Interview Questions
Scenario-Based Interview Questions
This section of questions will consist of various scenario based questions that you may face in your interviews.
Scenario 1:
Suppose a company built on monolithic architecture handles numerous products. Now, as the company expands in today’s scaling industry, their monolithic architecture started causing problems.
How do you think the company shifted from monolithic to microservices and deploy their services containers?
Solution:
As the company’s goal is to shift from their monolithic application to microservices, they can end up building piece by piece, in parallel and just switch configurations in the background. Then they can put each of these built-in microservices on the Kubernetes platform. So, they can start by migrating their services once or twice and monitor them to make sure everything is running stable. Once they feel everything is going good, then they can migrate the rest of the application into their Kubernetes cluster.
Scenario 2:
Consider a multinational company with a very much distributed system, with a large number of data centers, virtual machines, and many employees working on various tasks.
How do you think can such a company manage all the tasks in a consistent way with Kubernetes?
Solution:
As all of us know that I.T. departments launch thousands of containers, with tasks running across a numerous number of nodes across the world in a distributed system.
In such a situation the company can use something that offers them agility, scale-out capability, and DevOps practice to the cloud-based applications.
So, the company can, therefore, use Kubernetes to customize their scheduling architecture and support multiple container formats. This makes it possible for the affinity between container tasks that gives greater efficiency with an extensive support for various container networking solutions and container storage.
Scenario 3:
Consider a situation, where a company wants to increase its efficiency and the speed of its technical operations by maintaining minimal costs.
How do you think the company will try to achieve this?
Solution:
The company can implement the DevOps methodology, by building a CI/CD pipeline, but one problem that may occur here is the configurations may take time to go up and running. So, after implementing the CI/CD pipeline the company’s next step should be to work in the cloud environment. Once they start working on the cloud environment, they can schedule containers on a cluster and can orchestrate with the help of Kubernetes. This kind of approach will help the company reduce their deployment time, and also get faster across various environments.
Scenario 4:
Suppose a company wants to revise it’s deployment methods and wants to build a platform which is much more scalable and responsive.
How do you think this company can achieve this to satisfy their customers
?
Solution:
In order to give millions of clients the digital experience they would expect, the company needs a platform that is scalable, and responsive, so that they could quickly get data to the client website. Now, to do this the company should move from their private data centers (if they are using any) to any cloud environment such as AWS. Not only this, but they should also implement the microservice architecture so that they can start using Docker containers. Once they have the base framework ready, then they can start using the best orchestration platform available i.e. Kubernetes. This would enable the teams to be autonomous in building applications and delivering them very quickly.
Scenario 5:
Consider a multinational company with a very much distributed system, looking forward to solving the monolithic code base problem.
How do you think the company can solve their problem?
Solution
Well, to solve the problem, they can shift their monolithic code base to a microservice design and then each and every microservices can be considered as a container. So, all these containers can be deployed and orchestrated with the help of Kubernetes.
Scenario 6:
All of us know that the shift from monolithic to microservices solves the problem from the development side, but increases the problem at the deployment side.
How can the company solve the problem on the deployment side?
Solution
The team can experiment with container orchestration platforms, such as Kubernetes and run it in data centers. So, with this, the company can generate a templated application, deploy it within five minutes, and have actual instances containerized in the staging environment at that point. This kind of Kubernetes project will have dozens of microservices running in parallel to improve the production rate as even if a node goes down, then it can be rescheduled immediately without performance impact.
Scenario 7:
Suppose a company wants to optimize the distribution of its workloads, by adopting new technologies.
How can the company achieve this distribution of resources efficiently?
Solution
The solution to this problem is none other than Kubernetes. Kubernetes makes sure that the resources are optimized efficiently, and only those resources are used which are needed by that particular application. So, with the usage of the best container orchestration tool, the company can achieve the distribution of resources efficiently.
Scenario 8:
Consider a carpooling company wants to increase their number of servers by simultaneously scaling their platform.
How do you think will the company deal with the servers and their installation?
Solution
The company can adopt the concept of containerization. Once they deploy all their application into containers, they can use Kubernetes for orchestration and use container monitoring tools like Prometheus to monitor the actions in containers. So, with such usage of containers, giving them better capacity planning in the data center because they will now have fewer constraints due to this abstraction between the services and the hardware they run on.
Scenario 9:
Consider a scenario where a company wants to provide all the required hand-outs to its customers having various environments.
How do you think they can achieve this critical target in a dynamic manner?
Solution
The company can use Docker environments, to put together a cross-sectional team to build a web application using Kubernetes. This kind of framework will help the company achieve the goal of getting the required things into production within the shortest time frame. So, with such a machine running, the company can give the hands-outs to all the customers having various environments.
Scenario 10:
Suppose a company wants to run various workloads on different cloud infrastructure from bare metal to a public cloud.
How will the company achieve this in the presence of different interfaces?
Solution
The company can decompose its infrastructure into microservices and then adopt Kubernetes. This will let the company run various workloads on different cloud infrastructures.
Multiple Choice Interview Questions
This section of questions will consist of multiple choice interview questions, that are frequently asked in interviews.
Q1. What are minions in Kubernetes cluster?
-
They are components of the master node.
-
They are the work-horse / worker node of the cluster.[Ans]
-
They are monitoring engine used widely in kubernetes.
-
They are docker container service.
Q2. Kubernetes cluster data is stored in which of the following?
-
Kube-apiserver
-
Kubelet
-
Etcd[Ans]
-
None of the above
Q3. Which of them is a Kubernetes Controller?
-
ReplicaSet
-
Deployment
-
Rolling Updates
-
Both ReplicaSet and Deployment[Ans]
Q4. Which of the following are core Kubernetes objects?
-
Pods
-
Services
-
Volumes
-
All of the above[Ans]
Q5. The Kubernetes Network proxy runs on which node?
-
Master Node
-
Worker Node
-
All the nodes[Ans]
-
None of the above
Q6. What are the responsibilities of a node controller?
-
To assign a CIDR block to the nodes
-
To maintain the list of nodes
-
To monitor the health of the nodes
-
All of the above[Ans]
Q7. What are the responsibilities of Replication Controller?
-
Update or delete multiple pods with a single command
-
Helps to achieve the desired state
-
Creates a new pod, if the existing pod crashes
-
All of the above[Ans]
Q8. How to define a service without a selector?
-
Specify the external name[Ans]
-
Specify an endpoint with IP Address and port
-
Just by specifying the IP address
-
Specifying the label and api-version
Q9. What did the 1.8 version of Kubernetes introduce?
-
Taints and Tolerations[Ans]
-
Cluster level Logging
-
Secrets
-
Federated Clusters
Q10. The handler invoked by Kubelet to check if a container’s IP address is open or not is?
-
HTTPGetAction
-
ExecAction
-
TCPSocketAction[Ans]
-
None of the above
Good job bro... Keep up the good work and many thanks!
ReplyDeleteArticle is very useful, checkout this link also
ReplyDeleteDevOps Interview Questions with Answers
Docker Interview Questions with Answers
Git Interview Questions with Answers
Very Interesting post, must have a look.
ReplyDeleteDevOps Tutorial for Beginners, Devops Free Training Online
Kubernetes Tutorial – Full Kubernetes Course for Beginners
Ansible Tutorial for Beginners, Online Ansible Free Training
Docker Tutorial for Beginners, Online Docker Free Training
Openstack Tutorial for Beginners, Openstack training Online
How to Install Kubernetes Cluster on Ubuntu 20.04 LTS
Top 50 DevOps Interview Questions and Answers
DevOps Interview Questions and Answers
Learn Linux, DevOps and Cloud